Most industrial AI fails after the demo. Here are five deployment patterns where real factories are making it work in 2026 — predictive maintenance, vision QA, agentic supply-chain, copilots, and adaptive manufacturing — plus the four traits that separate the 5% that ship from the 95% that stall.
A widely cited MIT NANDA report from mid-2025 found that 95% of enterprise GenAI pilots return zero measurable value. CIO/IDC reporting tells the same story from a different angle: 88% of AI pilots never reach production at all. McKinsey's most recent State of AI survey lands in roughly the same neighborhood — most organizations are using AI in some form, but only a minority can point to measurable EBIT impact from it.
And yet — inside the same plants — AI systems are already stopping production lines, dispatching technicians, and approving freight spend in real time. A major steel producer replaced a manual inspection loop that hovered around 60–70% accuracy with an AI vision system that hit 98% precision and reportedly saved millions per year. Predictive maintenance deployments at automotive plants have, in vendor-reported case studies, paid back full IoT investments inside a single year off a single application class.
So what separates those two worlds?
It isn't the model. It almost never is.
Industrial AI doesn't fail because the models are bad. It fails because nothing around the model changes.
This article is about the 5%. What they did differently. The five deployment patterns where industrial AI is making it into production in 2026. And why most of the vendor landscape — even the well-known names — still isn't built for the deployment problem.
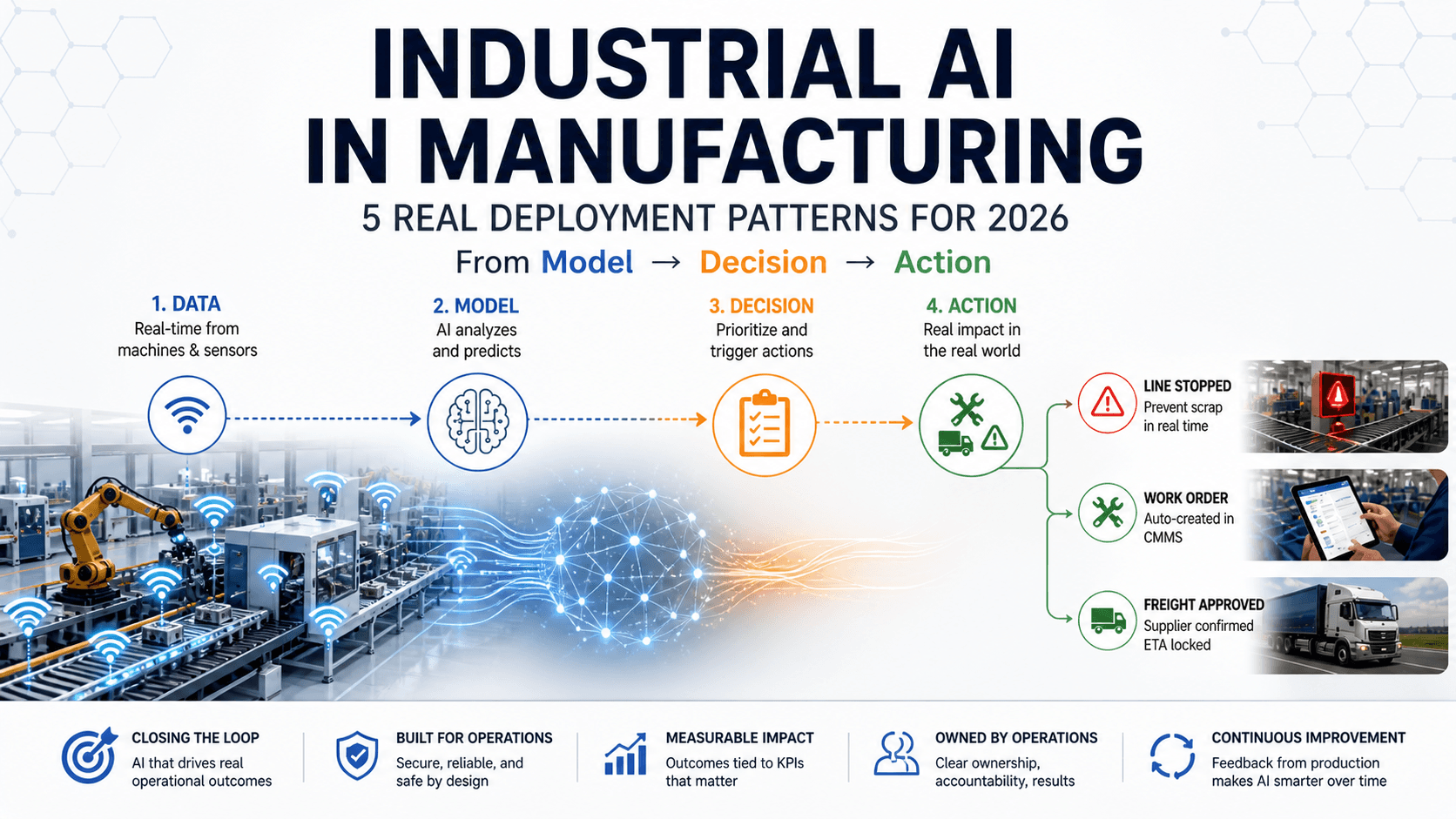
Industrial AI is the application of machine learning and agentic AI to physical manufacturing operations — sensors, equipment, supply chains, production lines — closing the decision loop against operational technology (OT) data, edge constraints, and safety-critical actions.
It's distinct from generic enterprise AI in three ways. The data is real-time and physical (vibration, vision, temperature, throughput) rather than text or document. The latency budget is tighter — sometimes sub-second for line-side use cases. And the cost of a wrong decision is much higher: a line stoppage, a scrap batch, a safety incident.
These three categories get conflated in vendor decks. They aren't the same thing.
Across the 2026 industrial-show cycle — particularly the Hannover Messe announcements and CES launches — the category is visibly moving from AI pilots toward AI-embedded workflows. Whether that translates into production-grade deployments is the open question this article is about.
The pilot phase of an industrial AI project is misleading by design. You pick a clean problem, a cooperative team, a curated dataset, and a small slice of the plant. The model performs. Everyone celebrates. Then the project tries to scale into production — and the wheels come off.
Here's what actually kills it. Not "lack of integration." Not "data quality." Be specific.
1. Models are built on static data extracts, not live plant systems. The pilot runs on a CSV pull from the historian. Production needs a streaming feed from MES or the data historian, with sub-second latency, with backfill handling, with sensor swap-outs. The data plumbing isn't scoped until late, by which point the project's credibility is thin.
2. "Check a dashboard" is passing for workflow change. The model produces an alert. The operator's standard operating procedure still says do exactly what they did before. The dashboard goes unread by week six. This is the most common failure mode and the most embarrassing — the model works, the people just have no reason to act on it.
3. There is no economic trigger. Ask the project lead: what decision changes when the model fires? If the answer is "we'll look at it" or "the team will be informed," it's a demo. A deployment has a defined economic action — a work order is created, a line is stopped, a freight quote is sent, an alternate supplier is sourced. No trigger, no deployment.
4. There is no feedback loop. The model is trained once on pilot data. Production data drifts — a new SKU, a sensor swap, a line reconfiguration, a seasonal supply shift. Accuracy decays. Nobody owns the retraining cadence. The system quietly becomes worse than the rule-based predecessor it replaced.
5. There is no accountable line owner. The pilot has a champion — usually a senior engineer or an ops director with momentum. Months later the champion is on a different project, the original sponsor has changed, and the deployment has nobody. Industry analyses consistently find that production-deployment rates in manufacturing remain in the low double digits, and unclear ownership is one of the most cited reasons.
There's a cost dimension too. BCG and other consultancies have flagged that infrastructure costs at production scale routinely run several times higher than initial pilot projections. Pilot economics often don't survive contact with production load. If the business case was thin to begin with, scale exposes it.
The pattern that BCG keeps pointing to in its 2025 reports is that the leaders redesign the workflow before deploying the technology. They don't layer AI onto unchanged operational procedures. They look at what the workflow needs to become, and then they pick where the AI plugs in.
Before evaluating any vendor, model, or platform, run a project against this checklist. Projects that score zero on more than one row are statistically unlikely to make it past pilot.
| Requirement | Why it matters |
|---|---|
| Live OT/MES/CMMS integration | Prevents demo-only data flows. Production needs a streaming feed, not a CSV. |
| Workflow owner | Ensures someone acts on model output. No owner, no deployment. |
| Economic trigger | Ties the AI output to a business decision. "We'll look at it" is a demo. |
| Feedback loop | Prevents model drift. Production data shifts; the model has to keep up. |
| Monitoring + budget controls | Critical for agentic systems where cost-per-inference can outpace savings. |
The patterns below all share these traits where they exist in production. Where any of these is missing, the deployment dies — no matter how good the model is.
(For more deployment-led manufacturing coverage and AI in manufacturing examples across the 2026 trade-show cycle, browse our manufacturing articles.)
The patterns below aren't experiments. They're the minority of cases where industrial AI actually makes it into production.
Each of these patterns ships consistently because the conditional in its name is built in — the workflow change, the economic trigger, the line authority, the budget cap. Take that conditional away and the pattern reverts to a stuck pilot.
Examples of AI in manufacturing — five patterns that ship. The "Core trigger" column is the load-bearing one: that's the decision the model is wired to make. No trigger, no deployment.
These patterns are not defined by the model they use. They're defined by the decision they are wired to make.
| Pattern | Where it lives | Core trigger | Maturity | Best-known anchor |
|---|---|---|---|---|
| Predictive maintenance | Equipment + CMMS | Work order auto-created | Proven | Siemens Senseye + Microsoft |
| Computer-vision QA | Production line + QMS | Line stop / part reject | Proven | Steel slab inspection (Matroid case) |
| Agentic supply-chain | ERP/TMS + agent layer | Spend decision committed | Scaling | Dow Chemical, CSX, C.H. Robinson |
| Industrial copilots | PLM/MES/CMMS overlay | SOP-driven action taken | Scaling | Siemens Industrial Copilot (100+ companies) |
| Adaptive manufacturing | Whole-factory architecture | Real-time re-optimization | Emerging | Siemens-NVIDIA Erlangen |
Why it ships. Predictive maintenance ships because the decision is already defined: create a work order. There is no "check a dashboard" version — the action is automatic and the economic trigger is pre-built into the workflow. That's why this pattern has the densest concentration of named-customer wins in industrial AI.
Real deployments.
Benchmark ROI ranges (industry-cited). Predictive-maintenance benchmarks commonly land in the 10:1 to 30:1 ROI range within 12–18 months, with reductions of unplanned downtime in the 30–50% band and maintenance-cost reductions of 18–25% versus preventive scheduling. These are benchmark ranges aggregated across vendor case studies, not guaranteed outcomes.
Integration footprint. Vibration, temperature, and usage sensors → data historian → AI inference (edge or cloud, depending on latency budget) → CMMS work-order trigger. The CMMS hookup is what separates a deployment from a pilot. Without it, alerts pile up and nothing happens.
Where it dies. A line gets reconfigured, a sensor model changes, a new product variant comes through — and the model isn't retrained. Accuracy quietly decays. Technicians start ignoring alerts because the false-positive rate has crept up. Within a quarter, the system is worse than the rule-based predecessor. The feedback loop is the make-or-break.
(For more on what predictive-maintenance vendors are actually shipping today — including Siemens Senseye and the broader Microsoft + Siemens deployment footprint — see our Hannover Messe 2026 Recap.)
Why it ships. A vision system that can only flag defects ends up where every dashboard ends up — ignored. A vision system with the authority to halt the line is structurally different. The model isn't producing an alert; it's making a decision. That's the deployment.
If the model cannot stop the line, it does not control quality.
Real deployments.
Industry context. The machine-vision market is on a documented growth trajectory — analyst forecasts widely place it in the tens of billions of dollars annually by 2030 — and a large majority of manufacturers report planning AI-vision deployments in the coming 18–24 months.
Integration footprint. Line-side high-resolution cameras → edge inference (modern stack: Vision Transformers and CNN ensembles) → tie-in to MES and the quality management system for traceability. Critically: a configured rule for the model to either stop the line or route a part to rework. That rule is what gives the model authority.
Where it dies. Lighting changes, SKU mix shifts, raw-material variation. If retraining isn't operationalized — meaning a person owns it on a schedule and a feedback channel exists — accuracy drops, false-positive rates spike, and the line stops trusting the system. The bypass starts small (one shift) and ends with the model functionally offline.
(Industrial vision-AI vendors cluster at major manufacturing shows — for an evaluation playbook covering vendor floor strategy, see our Hannover Messe 2026 Exhibitor's Guide.)
Why it ships. Agentic AI for supply chain is the pattern with the clearest economic trigger by definition — an agent that can spend money has unambiguous decision authority. It's also the pattern with the steepest cost-of-failure curve, which is why the budget cap is load-bearing. Done right, the agent makes thousands of small decisions per day that humans can't scale to. Done wrong, it loops, hallucinates a counterparty, or burns more in inference cost than it saves.
If an agent cannot commit spend, it is not a supply-chain system. It's a reporting tool.
Real deployments.
Microsoft's Supply Chain 2.0 reporting names several customers running production-grade agentic systems:
ROI signals. Reported productivity uplifts on adopted workflows typically land in the 20–30% range, alongside operational-cost reduction via space and material optimization. The economics are sensitive to inference-cost discipline: agentic systems without a tight budget cap can erase savings inside a quarter.
Integration footprint. ERP + TMS + supplier portals + an agent-orchestration layer. This last layer is the architectural net-new — most enterprises don't have it yet. LangGraph, OpenAI Agents SDK, and the agent runtimes inside Microsoft Copilot and SAP's Hannover Messe 2026 launches are all jockeying to become it.
Where it dies. Two failure modes. First: agents loop without a hard budget cap, and cost-per-inference quietly exceeds savings. Second: agents have no escalation path on edge cases and silently make wrong decisions at scale — issuing a quote against a defunct route, sourcing from a sanctioned supplier, paying a duplicate invoice. Both failure modes are recoverable if monitoring is in place. Without monitoring, neither is.
(Logistics, freight, and supply-chain decision-makers often surface at the spring trade-show cycle — see our April 2026 Trade Shows complete calendar for the broader landscape.)
Why it ships. Copilots are the cheapest pattern to deploy in pure data-plumbing terms. They sit on top of existing PLM, MES, CMMS, and ERP systems and don't require new sensors. The trade-off: they require the heaviest organizational change. The copilot is only useful if the operator's standard operating procedure is rewritten to incorporate it. Skip the SOP rewrite, and usage decays predictably at the 60-day mark.
The before/after that actually matters. A maintenance copilot is the cleanest illustration:
Same install. Three different outcomes. The SOP rewrite is what separates them.
Real deployments.
ROI signals. The metrics that matter here are technician hours saved, operator onboarding compression, and decision-cycle time — not classic predictive-maintenance dollars. Public anchors today are mostly Siemens-published; private numbers from the broader Copilot customer base will start appearing through 2026 as deployments mature.
Where it dies. The copilot is installed. The SOP isn't updated. The operator opens it once, finds it neither faster nor more authoritative than what they already do, and stops using it. By day 60, daily usage has dropped sharply. This is the pattern most likely to be reported as "deployed" while functionally being a sunk cost.
(Cloud-AI vendors driving the copilot stack — Microsoft, AWS, and the broader hyperscaler ecosystem — are easiest to evaluate in person at developer/cloud shows. See our AWS Summit 2026 guide for the cloud-AI exhibitor floor.)
Why it ships (eventually). Adaptive manufacturing — factories where production sequencing, robotics, and quality control all flex in real time based on AI-driven decisions — is the highest-ceiling pattern and the heaviest lift. It is not what you deploy in 2026 to hit a Q3 number. It is what you commit to in 2026 to compound operational learning that competitors can't catch up on.
What "adaptive" actually means in production. Production scheduling, robot routing, and QA inspection thresholds are continuously re-optimized based on real-time demand and defect signals — not on a daily batch run, not on a weekly engineering review. The factory is wired to change its own behavior every shift, sometimes every hour, against signals the planning systems used to surface to humans for slow decisions.
Real deployments.
ROI signals. Not yet quantified in any public way that's worth citing. The thesis is operational learning compounds — early movers handle edge cases that competitors won't see until they deploy years later.
Integration footprint. Heaviest of all five patterns. Either ground-up factory design or a major brownfield retrofit. Multi-year programs.
Where it dies. Anyone treating this pattern as a 12-month rollout instead of a 24–36 month commitment. Stranded-investment risk is real if leadership turns over mid-program.
The vendor landscape coming out of the 2026 show cycle is more usefully read as three clusters than as a flat list. Each cluster plays a different role in a deployment, and the most common procurement mistake is hiring tooling and assuming it adds up to a deployment.
PTC's ThingWorx exit is less about technology — and more about the difficulty of turning platforms into deployed systems.
A platform business that sold industrial connectivity in 2024 is a different business from one that sells deployed AI workflows in 2026. The category has moved.
For most enterprises, the right combination is one Operator + one Platform + targeted Tooling. The Operator owns the deployment outcome. The Platform anchors the data and process layer. Tooling fills component-level gaps.
The mistake — the one BCG and McKinsey both keep flagging in their 2025 reports — is hiring tooling and a platform, skipping an Operator, and assuming the customer organization will absorb the integration and workflow-redesign load itself. Customer orgs almost never do, and that's where most of the 95% lives.
For the full vendor breakdown from this year's biggest industrial AI showcase, see our Hannover Messe 2026 Recap.
What is industrial AI?
Industrial AI is the application of machine learning and agentic AI to physical manufacturing operations — sensors, equipment, supply chains, and production lines — closing the decision loop against operational technology (OT) data with real-time, edge, and safety-critical constraints.
How is industrial AI different from enterprise AI?
Three ways. The data is real-time and physical (vibration, vision, temperature, throughput) rather than text or document. The latency budget is tighter — often sub-second in line-side use cases. And the cost of a wrong decision is higher: line stoppage, scrap, or safety incident. Architecture, operations, and governance all differ as a result.
How is industrial AI different from Industry 4.0?
Industry 4.0 is the broader factory-modernization narrative — IoT, connectivity, digital twins, MES upgrades, data lakes. Industrial AI is the application layer that lives on top of that infrastructure. You can have Industry 4.0 without industrial AI. You can't have meaningful industrial AI without Industry 4.0 underneath.
What's a realistic ROI for an industrial AI deployment?
It depends on the pattern. Predictive maintenance benchmarks commonly land in the 10:1 to 30:1 range within 12–18 months. Computer-vision QA can run higher when accuracy improvements are large. Industrial copilots are typically measured in technician-hours saved rather than direct dollars. Agentic supply-chain returns track to roughly 20–30% workforce productivity uplift on adopted workflows. Adaptive manufacturing has no public ROI baseline yet.
Why do most industrial AI pilots fail?
Five recurring causes: models built on static data extracts instead of live plant systems, "check a dashboard" passing for workflow change, no defined economic trigger when the model fires, no feedback loop to retrain on production data, and no accountable line owner past the pilot champion. Infrastructure costs at production scale also routinely run several times higher than initial pilot projections, exposing thin business cases.
Should I deploy on-prem, edge, or cloud?
Edge for latency-critical inference (vision QA, real-time control). Cloud for training, multi-site analytics, and supply-chain optimization. On-prem when regulatory or data-sovereignty constraints require it (defense, regulated pharma). Most production deployments end up hybrid — edge inference, cloud training, on-prem data residency for sensitive segments.
What's the actual difference between an AI demo and an AI deployment?
A demo shows that the model can produce an output. A deployment integrates that output into a workflow with a defined economic trigger, an accountable owner, a feedback loop, and a monitoring/eval harness. The model is the same in both cases. Everything around the model is different — and everything around the model is the deployment.
Which vendor cluster — Operator, Platform, or Tooling — should I evaluate first?
Start with Operators. They own the deployment outcome and will tell you which platform and which tooling fit your existing data and workflow architecture. Evaluating platforms first tends to produce sunk-cost decisions that constrain the deployment options later.
The five patterns in this article — predictive maintenance, computer-vision QA, agentic supply-chain, industrial copilots, adaptive manufacturing — aren't five different bets. They're five different places where the same five traits show up: live system integration, workflow ownership, an economic trigger, a feedback loop, and proper monitoring. Where those traits are present, the deployment ships. Where they aren't, it joins the 95%.
The vendor landscape is reorganizing around exactly this realization. PTC's exit from ThingWorx is the loudest signal of it. Capgemini's shift toward end-to-end agentic deployment is the quietest. Siemens-NVIDIA at Erlangen is somewhere in between.
In 2026, industrial AI stopped being a modeling problem. It became an operations problem — and most organizations are still staffed for the old one.
The companies that internalize that shift this year are the ones that will be quoted in next year's case studies.
Where to go next:
